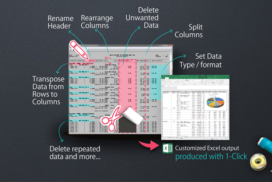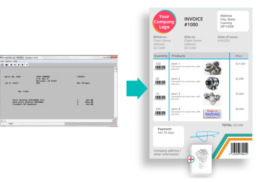
In this article, we address the common challenges facing users when extracting data from Baan and Infor LN, and we propose a solution through a use case about a new data analyst at the company “Wectechny.”
Case
A new data analyst joined Wectechny* and was to report directly to the CEO. He was asked to extract data and carry out its analysis for an upcoming important board report; he needed to get data from the Baan ERP system quickly.
Obstacle #1
When he approached the IT team asking for access through the company’s reporting system, he was told that using it requires training and knowledge of the special programming language it uses. Given his experience in IT, he knew there had to be easier, and in return, faster alternatives. He asked if he could have access to the database through ODBC for running queries.
Obstacle #2
Little did he know that ODBC by itself would be hard to use. The unique naming and structure of Baan’s tables and fields require extensive user experience in the system; it would take an unnecessarily long time until he can make a few meaningful queries —looking up names and meanings with every step of data extraction.
A way out
At last, a programmer suggested that the best way for him to get data quickly would be through an easy to use system that is built to understand the complexities of Baan and deals with them—a system that would allow the newly-hired data analyst to extract and use data from the Baan’s database easily, quickly and efficiently.
What are these Baan/Infor LN database complexities?
- Baan/ Infor LN Data dictionary: Baan and Infor LN use abbreviations for naming fields and tables. Since most people struggle memorizing and understanding such abbreviations when selecting tables or fields for extracting data, they would most likely need to bounce between the database and the data dictionary of Baan that is stored in internal tables; keep in mind that there are thousands of tables, each with tens of fields to bounce in and out of.
- The second problem is that in Baan and Infor LN’s database, tables of the same type residing in different companies are stored as different tables. This means that when you build a report for, say, the purchase orders of company 300, you will use table “tdpur041300” (the last 3 characters specify the number of the company in the database.) The report will be perceived in Baan as applicable only to the purchase order report of company 300, when in practice, it’s applicable to the purchase order reports of all companies in Baan’s database.
This structure will need you to write a separate report for tdpur041300, tdpur041400, tdpur041500 (For company 300, 400,500), and so on. The reason why these tables are not classified as identical is that in each of their “names,” the number of the company is included. This is, of course, a matter of algorithms, and when we come in as users, we realize that these tables are basically the same. We would need to do the extra manual work of coding, copying, and pasting to rewrite a whole report for each company.
- The third problem is handling text in Baan and Infor LN database
Text fields in Baan/LN are stored in specific tables, in binary format; generic systems do not know how to get the value of such text.
- The fourth problem is handling enumerated fields: going directly to the database using ODBC will not let you understand the Baan/Infor LN “enumerated fields”. This is because the values are displayed by meaningless numbers without any reference to their contextual meaning. In this case, the user would need to search for, collect, and “translate” these numerical values/ numbers into meaningful text or other relevant values. For instance, a field that stands for “Item type in Maintain item data” is abbreviated as “kitm.” When defining the item type, the value displayed is an irrelevant number:
- Purchased = 1
- Manufactured = 2
- Generic = 3
- Cost = 4
- Service = 5
- Subcontracting = 6
With ODBC, you will only see the number, but the meaning of this number is found somewhere else.
All of these complexities made it clear to the data analyst that there had to be a solution tool that makes the process he’s about to carry out less hectic. After proposing his problem to the company’s consulting group, he was introduced to B2Win Suite, reporting application built to deal with all the previously mentioned complexities and more.
How?
Solutions:
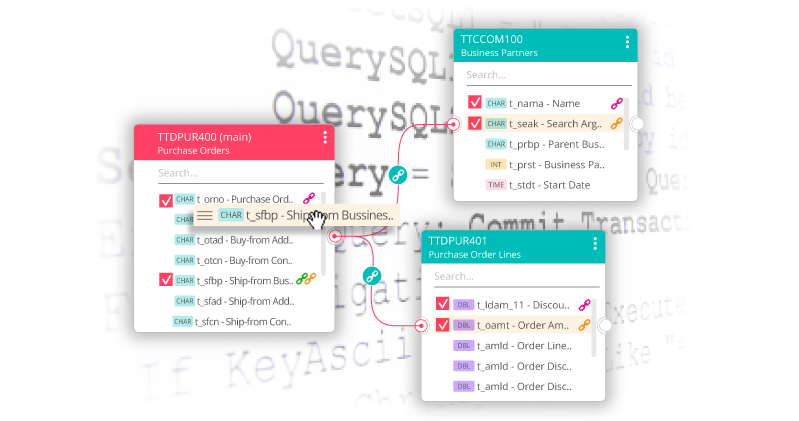
- Baan Data dictionary integration: B2Win Suite is built with the Baan Data Dictionary integrated in its system. The user can simply search for tables and fields through typing part of the presumed description of such destinations.
Example of Baan data dictionary:
Instead of looking for table tdpur041, search for “Purchase Order Lines”.
Instead of looking for the field amta while on table tdpur041, search for “Amount”.
Example of Infor LN data dictionary:
Instead of looking for table tcibd100, search for “Item Inventory.”
Instead of looking for the field “stoc” while on table tcibd100, search for “Inventory on Hand”.
- Advanced classification of tables:
B2Win’s creators understand that although tables of the same type in different companies in Baan are stored as different tables, a query for a report on one of these companies should be applicable for others. Thus B2Win built a feature that automatically applies the report to a company without the need to write and maintain different queries for each company.
- Handling text in BAAN and Infor LN
Text fields in Baan/LN are stored in binary fields in a separate table. B2Win knows how to translate them to real text and make it available for users.
- Handling enumerated fields:
B2Win Suite displays the integrated and comprehensible meaning of enumerated fields by immediately translating these fields in the tables of reports from numerical values into relevant text descriptions.
To see NAZDAQ’s product for extracting data from Infor LN/Baan, please visit B2Data – B2Win Suite
Conclusion
The data analyst realized that it would be in his and the company’s best interests to use this affordable tool to finish the data analysis project quickly. By that, he would be leaving a great first impression of efficiency and helping the CEO have the data needed for the board meetings without technically-caused delays.
*Wectechny is a nickname for a company we worked with, and the story in this article is similar to theirs. We have changed details for the sole reason of respecting the company’s privacy.